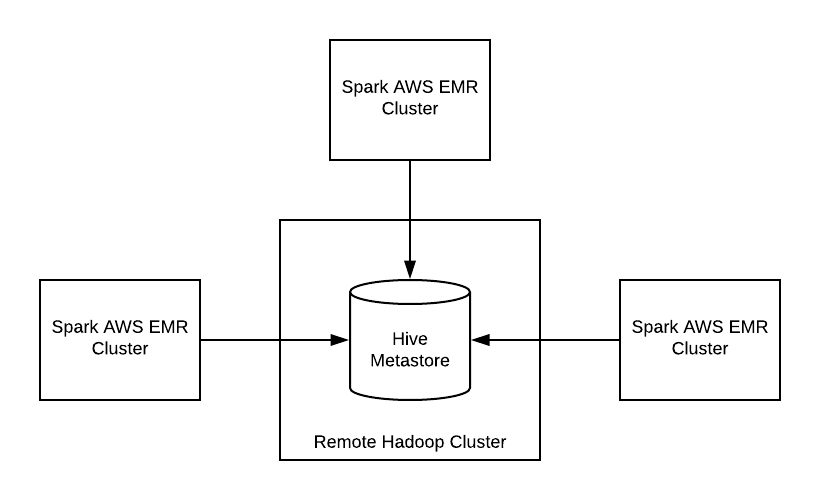
The graphic above depicts a common workflow for running Spark SQL apps. The Hive metastore holds table schemas (this includes the location of the table data), the Spark clusters, AWS EMR clusters in this case are treated as ephemeral, they spin up, run their application(s) and terminate.
This setup enables you to run multiple Spark SQL applications without having to worry about correctly configuring a multi-tenant Hive cluster.
Note: All examples are written in Scala 2.11 with Spark SQL 2.3.x. Prior experience with Apache Spark is pre-requisite.
Topics this post will cover:
- Running Spark SQL with Hive.
- Connecting to a remote Hive cluster.
- Connecting to a remote Hive cluster with HA (High Availability) enabled.
Running Spark SQL with Hive
Spark SQL supports the HiveQL syntax as well as Hive SerDes and UDFs, allowing you to access existing Hive warehouses. Connecting to a Hive metastore is straightforward - all you need to do is enable hive support while instantiating the SparkSession.
1
2
3
4
5
6
7
8
9
10
11
import org.apache.spark.sql.SparkSession
// warehouseLocation points to the default location for managed databases and tables
val warehouseLocation = new File("spark-warehouse").getAbsolutePath
val spark = SparkSession
.builder()
.appName("Simple Spark SQL App")
.config("spark.sql.warehouse.dir", warehouseLocation)
.enableHiveSupport()
.getOrCreate()
This assumes that the Spark application is co-located with the Hive installation.
Connecting to a remote Hive cluster
In order to connect to a remote Hive cluster, the SparkSession needs to know where the Hive metastore is located. This is done by specifying the hive.metastore.uris property.
This property can be found in the hive-site.xml file located in the /conf directory on the remote Hive cluster, for Horton Data Platform (HDP) and AWS EMR the location is /etc/hive/conf/hive-site.xml. Only a sub-set of all the properties mentioned in the file are needed.
Create a file named hive-site.xml with the following configuration:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://[ip-to-hive-metastore]:9083</value>
</property>
<property>
<name>hive.metastore.client.connect.retry.delay</name>
<value>5</value>
</property>
<property>
<name>hive.metastore.client.socket.timeout</name>
<value>1800</value>
</property>
</configuration>
Note: Although hive.metastore.client.connect.retry.delay and hive.metastore.client.socket.timeout are nice to have properties in a production environment, they aren’t mandatory.
This file needs to be passed as a parameter when running the spark-submit command as follows:
1
2
3
4
5
6
7
spark-submit \
--master yarn \
--deploy-mode cluster \
--files hive-site.xml \
--class com.oliver.SparkSqlExample \
...
...
And that’s about it, the code to create the SparkSession remains exactly the same as mentioned above.
Connecting to a remote Hive cluster with HA (High Availability) enabled
This is where things start to get interesting. In addition to location of the remote metastore, for HA (High Availability) enabled Hive clusters the SparkSession needs to know about DFS Nameservice configuration.
These properties can be found in the hdfs-site.xml file located in the /conf directory on the remote Hive cluster, for Horton Data Platform (HDP) and AWS EMR the location is /etc/hadoop/conf/hdfs-site.xml. Only a sub-set of the all the properties mentioned in the file are needed.
Create a file named hdfs-site.xml with the following configuration:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
<configuration>
<property>
<name>dfs.nameservices</name>
<value>[HA-namenode-nameservice]</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.[HA-namenode-nameservice]</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.namenodes.[HA-namenode-nameservice]</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.[HA-namenode-nameservice].nn1</name>
<value>[namenode-one-address]:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.[HA-namenode-nameservice].nn2</name>
<value>[namenode-two-address]:8020</value>
</property>
</configuration>
Note: The configuration above assumes the HDFS cluster has been configured with two Name Nodes i.e. nn1 and nn2.
Finally, both hive-site.xml and hdfs-site.xml need to be passed as parameters to the spark-submit command.
1
2
3
4
5
6
7
spark-submit \
--master yarn \
--deploy-mode cluster \
--files hive-site.xml,hdfs-site.xml \
--class com.oliver.SparkSqlExample \
...
...