Most modern data lakes are built using some sort of distributed file system (DFS) like HDFS or cloud based storage like AWS S3. One of the underlying principles followed is the “write-once-read-many” access model for files. This is great for working with large volumes of data- think hundreds of gigabytes to terabytes.
However, when building an analytical data lake, it is not uncommon to have data that gets updated. Depending on your use case, these updates could be as frequent as hourly to probably daily or weekly updates. You may also need to run analytics over the most up-to-date view, historical view containing all the updates or even just the latest incremental view.
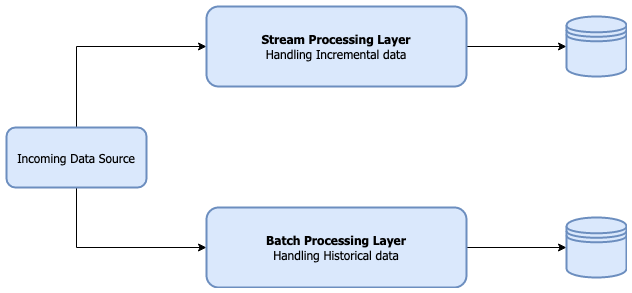
Very often this leads to having separate systems for stream and batch processing, the former handling incremental data while the latter dealing with historical data.
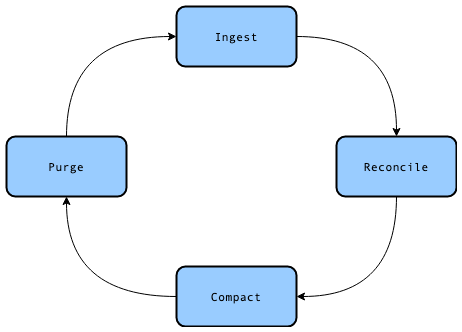
A common workflow to maintain incremental updates when working with data stored on HDFS is the Ingest-Reconcile-Compact-Purge strategy described here.
Here’s where a framework like Apache Hudi comes into play. It manages this workflow for us under the hood which leads to our core application code being a lot cleaner. Hudi supports queries over the most up-to-date view of the data as well as incremental changes at a point in time.
This post will introduce the core Hudi concepts and working with Copy on Write tables.
You may follow along with the source code here
Outline
- Prerequisites and framework versions
- Core Hudi concepts
- Initial Setup and Dependencies
- Working with CoW tables
Prerequisites and framework versions
Prior knowledge of writing spark jobs in scala and reading and writing parquet files would ease understanding of this post.
Framework versions
- JDK: openjdk version 1.8.0_242
- Scala: version 2.12.8
- Spark: version 2.4.4
- Hudi Spark bundle: version 0.5.2-incubating
Note: At the time of writing this post, AWS EMR comes bundled with Hudi v0.5.0-incubating which has a bug that causes upsert operations to freeze or take a long time to complete. You can read more about the issue here. The issue has been fixed in the current version of Hudi. If you plan on running on your code on AWS EMR you may want to consider overriding the bundled version with the latest version.
Core Hudi concepts
Let’s start off with some of the core concepts that need to be understood.
Types of Tables
Hudi supports two types of tables:
-
Copy on Write (CoW): When writing to a CoW table, the Ingest-Reconcile-Compact-Purge cycle is run. Data in CoW tables will always be up-to-date with the latest records after every write operation. This mode is preferred for use cases that need to read the most up-to-date data as quickly as possible. Data is exclusively stored in the columnar file format (parquet) in CoW tables. Since every write operation involves compaction and overwrite, this mode produces the smallest files.
-
Merge on Read (MoR): MoR tables are focused on fast write operations. Writing to these tables creates delta files which are later compacted to produce the up-to-date data on reading. The compaction operation may be done synchronously or asynchronously. Data is stored in a combination of columnar file format (parquet) as well as row based file format (avro).
Here are some of the trade-offs between the two table formats as mentioned in the Hudi documentation.
| Trade-off | CoW | MoR |
|---|---|---|
| Data Latency | Higher | Lower |
| Update cost (I/O) | Higher (rewrite entire parquet) | Lower (append to delta log) |
| Parquet File Size | Smaller (high update(I/0) cost) | Larger (low update cost) |
| Write Amplification | Higher | Lower (depending on compaction strategy) |
Types of Queries
Hudi supports two main types of queries, “Snapshot Queries” and “Incremental Queries”. In addition to the two main types of queries, MoR tables support “Read Optimized Queries”.
-
Snapshot Queries: Snapshot queries return the latest view of the data in case of CoW tables and a near real-time view with MoR tables. In the case of MoR tables, a snapshot query will merge the base files and the delta files on the fly, hence you can expect some latency. With CoW, since writes are responsible for merging, reads are quick since you only need to read the base files.
-
Incremental Queries: Incremental queries allow you to view data after a particular commit time by specifying a “begin” time or at a point in time by specifying a “begin” and an “end” time.
-
Read Optimized Queries: For MoR tables, read optimized queries return a view which only contains the data in the base files without merging delta files.
Important properties when writing out a Dataframe in Hudi format
-
hoodie.datasource.write.table.type- This defines the table type- the default value isCOPY_ON_WRITE. For a MoR table, set this value toMERGE_ON_READ. -
hoodie.table.name- This is a mandatory field and every table you write should have a unique name. -
hoodie.datasource.write.recordkey.field- Think of this as the primary key of your table. The value for this property is the name of the column in your Dataframe which is the primary key. -
hoodie.datasource.write.precombine.field- When upserting data, if there exists two records with the same primary key, the value in this column will decide which records get upserted. Selecting a column like timestamp will ensure that the record with the latest timestamp is picked. -
hoodie.datasource.write.operation- This defines the type of write operation. The possible values areupsert,insert,bulk_insertanddelete,upsertis the default.
Initial Setup and Dependencies
Declaring the dependencies
In order to use Hudi with your Spark jobs you’ll need the spark-sql, hudi-spark-bundle and spark-avro dependencies. Additionally you’ll need to configure Spark to use the KryoSerializer.
Here a snippet of the pom.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.12.8</scala.version>
<scala.compat.version>2.12</scala.compat.version>
<spec2.version>4.2.0</spec2.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.compat.version}</artifactId>
<version>2.4.4</version>
</dependency>
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-spark-bundle_${scala.compat.version}</artifactId>
<version>0.5.2-incubating</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-avro_${scala.compat.version}</artifactId>
<version>2.4.4</version>
</dependency>
</dependencies>
Setting up the schema
We’ll use the following Album case class to represent the schema of our table.
1
case class Album(albumId: Long, title: String, tracks: Array[String], updateDate: Long)
Creating some test data
Let’s create some data we’ll use for the upsert operation.
Things to notice:
INITIAL_ALBUM_DATAhas two records with the key801UPSERT_ALBUM_DATAcontains one updated record and two new records.
1
2
3
4
5
6
7
8
9
10
11
12
13
def dateToLong(dateString: String): Long = LocalDate.parse(dateString, formatter).toEpochDay
private val INITIAL_ALBUM_DATA = Seq(
Album(800, "6 String Theory", Array("Lay it down", "Am I Wrong", "68"), dateToLong("2019-12-01")),
Album(801, "Hail to the Thief", Array("2+2=5", "Backdrifts"), dateToLong("2019-12-01")),
Album(801, "Hail to the Thief", Array("2+2=5", "Backdrifts", "Go to sleep"), dateToLong("2019-12-03"))
)
private val UPSERT_ALBUM_DATA = Seq(
Album(800, "6 String Theory - Special", Array("Jumpin' the blues", "Bluesnote", "Birth of blues"), dateToLong("2020-01-03")),
Album(802, "Best Of Jazz Blues", Array("Jumpin' the blues", "Bluesnote", "Birth of blues"), dateToLong("2020-01-04")),
Album(803, "Birth of Cool", Array("Move", "Jeru", "Moon Dreams"), dateToLong("2020-02-03"))
)
Initializing the Spark context
Finally we’ll initialize the Spark context. One important point to note here is the use of the KryoSerializer.
1
2
3
4
5
6
val spark: SparkSession = SparkSession.builder()
.appName("hudi-datalake")
.master("local[*]")
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.config("spark.sql.hive.convertMetastoreParquet", "false") // Uses Hive SerDe, this is mandatory for MoR tables
.getOrCreate()
Working with CoW tables
In this section we’ll go over writing, reading and deleting records when working with CoW tables.
Base path & Upsert method
Let’s define a basePath where the table will be written along with an upsert method. The method will write the Dataframe in the org.apache.hudi format. Notice that all the Hudi properties that were discussed above have been set.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
val basePath = "/tmp/store"
private def upsert(albumDf: DataFrame, tableName: String, key: String, combineKey: String) = {
albumDf.write
.format("hudi")
.option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY, DataSourceWriteOptions.COW_TABLE_TYPE_OPT_VAL)
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, key)
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, combineKey)
.option(HoodieWriteConfig.TABLE_NAME, tableName)
.option(DataSourceWriteOptions.OPERATION_OPT_KEY, DataSourceWriteOptions.UPSERT_OPERATION_OPT_VAL)
// Ignore this property for now, the default is too high when experimenting on your local machine
// Set this to a lower value to improve performance.
// I'll probably cover Hudi tuning in a separate post.
.option("hoodie.upsert.shuffle.parallelism", "2")
.mode(SaveMode.Append)
.save(s"$basePath/$tableName/")
}
Initial Upsert
Insert INITIAL_ALBUM_DATA, we should have 2 records created and for 801,the record with date 2019-12-03.
1
2
3
val tableName = "Album"
upsert(INITIAL_ALBUM_DATA.toDF(), tableName, "albumId", "updateDate")
spark.read.format("hudi").load(s"$basePath/$tableName/*").show()
Reading a CoW table is as simple as a regular spark.read with format("hudi").
1
2
3
4
5
6
7
// Output
+-------------------+--------------------+------------------+----------------------+--------------------+-------+-----------------+--------------------+----------+
|_hoodie_commit_time|_hoodie_commit_seqno|_hoodie_record_key|_hoodie_partition_path| _hoodie_file_name|albumId| title| tracks|updateDate|
+-------------------+--------------------+------------------+----------------------+--------------------+-------+-----------------+--------------------+----------+
| 20200412182343| 20200412182343_0_1| 801| default|65841d0a-0083-447...| 801|Hail to the Thief|[2+2=5, Backdrift...| 18233|
| 20200412182343| 20200412182343_0_2| 800| default|65841d0a-0083-447...| 800| 6 String Theory|[Lay it down, Am ...| 18231|
+-------------------+--------------------+------------------+----------------------+--------------------+-------+-----------------+--------------------+----------+
Another way to be sure is to look at the Workload profile log output.
1
Workload profile :WorkloadProfile {globalStat=WorkloadStat {numInserts=2, numUpdates=0}, partitionStat={default=WorkloadStat {numInserts=2, numUpdates=0}}}
Updating Records
1
upsert(UPSERT_ALBUM_DATA.toDF(), tableName, "albumId", "updateDate")
Let’s look at the Workload profile and verify that it is as expected
1
Workload profile :WorkloadProfile {globalStat=WorkloadStat {numInserts=2, numUpdates=1}, partitionStat={default=WorkloadStat {numInserts=2, numUpdates=1}}}
Let’s look at the output
1
2
3
4
5
6
7
8
9
10
11
spark.read.format("hudi").load(s"$basePath/$tableName/*").show()
//Output
+-------------------+--------------------+------------------+----------------------+--------------------+-------+--------------------+--------------------+----------+
|_hoodie_commit_time|_hoodie_commit_seqno|_hoodie_record_key|_hoodie_partition_path| _hoodie_file_name|albumId| title| tracks|updateDate|
+-------------------+--------------------+------------------+----------------------+--------------------+-------+--------------------+--------------------+----------+
| 20200412183510| 20200412183510_0_1| 801| default|65841d0a-0083-447...| 801| Hail to the Thief|[2+2=5, Backdrift...| 18233|
| 20200412184040| 20200412184040_0_1| 800| default|65841d0a-0083-447...| 800|6 String Theory -...|[Jumpin' the blue...| 18264|
| 20200412184040| 20200412184040_0_2| 802| default|65841d0a-0083-447...| 802| Best Of Jazz Blues|[Jumpin' the blue...| 18265|
| 20200412184040| 20200412184040_0_3| 803| default|65841d0a-0083-447...| 803| Birth of Cool|[Move, Jeru, Moon...| 18295|
+-------------------+--------------------+------------------+----------------------+--------------------+-------+--------------------+--------------------+----------+
Querying Records
The way we’ve been looking at our data above is known as a “Snapshot query”, this being the default. Another query that’s supported is an “Incremental query”.
Incremental Queries
To perform an incremental query, we’ll need to set the hoodie.datasource.query.type property to incremental when reading as well as specify the hoodie.datasource.read.begin.instanttime property. This will read all records after the specified instant time, for our example here, looking at the _hoodie_commit_time colum we have two distinct values, we’ll specify an instant time of 20200412183510.
1
2
3
4
5
6
spark.read
.format("hudi")
.option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY, DataSourceReadOptions.QUERY_TYPE_INCREMENTAL_OPT_VAL)
.option(DataSourceReadOptions.BEGIN_INSTANTTIME_OPT_KEY, "20200412183510")
.load(s"$basePath/$tableName")
.show()
This will return all records after commit time 20200412183510 which should be 3.
1
2
3
4
5
6
7
+-------------------+--------------------+------------------+----------------------+--------------------+-------+--------------------+--------------------+----------+
|_hoodie_commit_time|_hoodie_commit_seqno|_hoodie_record_key|_hoodie_partition_path| _hoodie_file_name|albumId| title| tracks|updateDate|
+-------------------+--------------------+------------------+----------------------+--------------------+-------+--------------------+--------------------+----------+
| 20200412184040| 20200412184040_0_1| 800| default|65841d0a-0083-447...| 800|6 String Theory -...|[Jumpin' the blue...| 18264|
| 20200412184040| 20200412184040_0_2| 802| default|65841d0a-0083-447...| 802| Best Of Jazz Blues|[Jumpin' the blue...| 18265|
| 20200412184040| 20200412184040_0_3| 803| default|65841d0a-0083-447...| 803| Birth of Cool|[Move, Jeru, Moon...| 18295|
+-------------------+--------------------+------------------+----------------------+--------------------+-------+--------------------+--------------------+----------+
Deleting Records
The last operation we’ll look at is delete. Delete is similar to upsert, we’ll need a Dataframe of the records that need to be deleted. The entire row isn’t necessary, we only need keys, as you’ll see in the sample code below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
val deleteKeys = Seq(
Album(803, "", null, 0l),
Album(802, "", null, 0l)
)
import spark.implicits._
val df = deleteKeys.toDF()
df.write.format("hudi")
.option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY, DataSourceWriteOptions.COW_TABLE_TYPE_OPT_VAL)
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "albumId")
.option(HoodieWriteConfig.TABLE_NAME, tableName)
// Set the option "hoodie.datasource.write.operation" to "delete"
.option(DataSourceWriteOptions.OPERATION_OPT_KEY, DataSourceWriteOptions.DELETE_OPERATION_OPT_VAL)
.mode(SaveMode.Append) // Only Append Mode is supported for Delete.
.save(s"$basePath/$tableName/")
spark.read.format("hudi").load(s"$basePath/$tableName/*").show()
This is all that this part covers. In Part 2 we’ll explore working with Merge on Read tables.